How to Search Event Photos Using Natural Language AI (2026 Guide)
Pixeva Team
How to Search Event Photos Using Natural Language AI (2026 Guide)
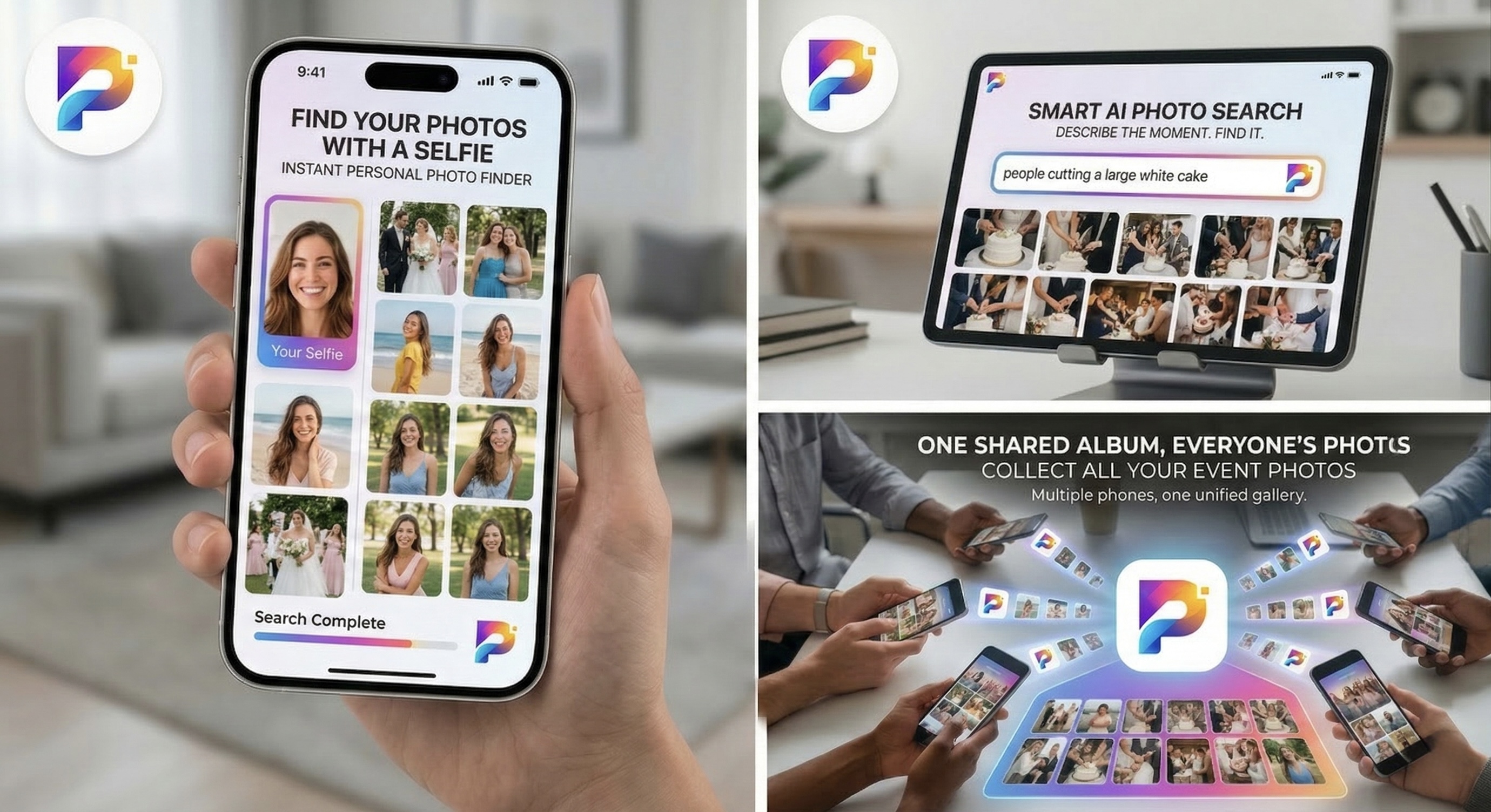
Type "bride throwing the bouquet" and get photos of that moment — not because someone typed tags for every frame, but because the system understands what you mean. That is semantic (natural language) search for event photos: you describe the scene; AI finds visual matches.
Traditional galleries break down fast: filenames like IMG_4729.jpg, missing tags, different words for the same thing ("bouquet" vs "flowers"), and scenes that are hard to label ("everyone laughing on the dance floor"). This guide explains how natural-language search works, what to type for weddings, conferences, and parties, and how Pixeva approaches it.
What is semantic search?
Keyword search looks for literal matches in text — tags, captions, or filenames. If nothing contains the word you typed, you see nothing.
Semantic search focuses on meaning. It connects:
- Your plain-language query ("outdoor ceremony at sunset")
- To what actually appears in each image (people, actions, objects, setting, mood)
So you can search the way you talk to a friend: "photos where we're all laughing" instead of guessing how the photographer labeled files.
Quick contrast
| Keyword-style | Semantic-style |
|---|---|
| Must match specific words | Matches ideas and scenes |
| Depends on tags | Works even when tags were never added |
| "bouquet" only if tagged | "bride throwing flowers" can still find the right moment |
How Pixeva's AI search works (simple version)
Behind a simple search box, several things happen:
-
Understanding photos — The system builds a rich representation of what is in each image: activities (dancing, speaking), objects (cake, stage), setting (indoor, beach), groups, and more — not just file names.
-
Understanding your query — Your sentence is interpreted as intent: what kind of moment, people, or environment you care about.
-
Matching by meaning — The query and images are compared in a meaning space (often using embeddings). Closest matches rise to the top.
-
Ranking — Results are ordered by relevance so the strongest matches appear first.
-
Speed — Designed to stay responsive even with large galleries (thousands of photos), using modern retrieval and vector search (for example with pgvector-style similarity) so you are not manually scrolling folders.
For guests and organizers, the experience stays simple: one box, plain English, fast results.
Example queries that work
Below are illustrative queries. Exact results depend on your gallery and how photos were shot — but this is the kind of language that works well.
Weddings
- "bride and groom first kiss" — Ceremony peak moments
- "champagne toast" — Glasses raised, celebration
- "cutting the wedding cake" — Classic staged moment
- "bridesmaids laughing together" — Group emotion
- "outdoor ceremony sunset" — Time-of-day + location cues
Try variations: "golden hour couple photo", "walking down the aisle", "first dance".
Conferences and corporate events
- "keynote speaker on stage" — Presentation context
- "networking in the lobby" — Mingling and badges
- "panel discussion" — Multiple seated speakers
- "audience questions" — Q&A energy
Parties and celebrations
- "everyone dancing" — Dance floor energy
- "group photo with birthday cake" — Cake + people
- "balcony at sunset" — Scene + light
Tip: Add verbs and context ("on the dance floor", "by the cake") instead of one-word searches.
Why this beats "tag everything" workflows
- No manual tagging marathon — Large weddings often mean hundreds or thousands of images; expecting perfect tags for every frame is unrealistic.
- Guests think in scenes — They remember moments, not filenames.
- Synonyms and paraphrases — Semantic models cope better than strict keyword lists.
- Surprise wins — Queries like "candid laughter" can surface moments nobody thought to tag.
AI search does not replace curators; it helps everyone find moments faster.
Tips for better searches
- Be specific — "First dance" beats "dance" alone.
- Describe the scene — Who + what + where: "speakers on stage with screen behind them".
- Try rephrasing — If one wording misses, try another ("toast" vs "speeches").
- Combine cues — "Outdoor group photo golden hour" merges setting + lighting.
- Think like a caption — Write what you would say in a text to a friend.
Weak: "party"
Stronger: "dance floor lights group celebrating"
Who it's for
- Guests — Find their moments without scrolling every upload.
- Photographers — Deliver a gallery that feels premium and searchable.
- Event hosts — Fewer "can you find the photo where…?" messages after the event.
Getting started with Pixeva
You can create an account and run events on Pixeva with a free tier that includes core gallery features (limits apply — for example 100 photos per event on the free plan). AI semantic search is a power feature: event owners enable it where their plan supports AI Search (for example Pro, Business, or Event Pass — see current pricing). Check your plan and event settings so AI Search is turned on for guests when you want natural-language discovery.
Next step: Visit Pixeva, open your event settings, and confirm AI Search is enabled for your tier — then share your guest link and let people search the way they actually think.
Key takeaways
- Semantic search matches meaning, not just filenames or tags.
- Plain-language queries match how people remember events.
- Pixeva combines modern AI with fast retrieval for real galleries at scale.
- Better queries — specific, scene-based, natural — mean better results.
Try Pixeva for your next event and give guests a gallery that understands questions, not just filenames: https://pixeva.co